[1] Chitta,驾驶军方解 K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A., Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence 2022, 45 (11), 12878-12895. |
[2] Liao, B.; Chen, S.; Yin, H.; Jiang, B.; Wang, C.; Yan, S.; Zhang, X.; Li, X.; Zhang, Y.; Zhang, Q. In Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving, Proceedings of the Computer Vision and Pattern Recognition Conference, 2025; pp 12037-12047. |
[3] Li, Z.; Yao, W.; Wang, Z.; Sun, X.; Chen, J.; Chang, N.; Shen, M.; Wu, Z.; Lan, S.; Alvarez, J. M., Generalized Trajectory Scoring for End-to-end Multimodal Planning. arXiv preprint arXiv:2506.06664 2025. |
[4] Wang, P.; Bai, S.; Tan, S.; Wang, S.; Fan, Z.; Bai, J.; Chen, K.; Liu, X.; Wang, J.; Ge, W., Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191 2024. |
[5] Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J., Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 2025. |
[6] Lee, Y.; Hwang, J.-w.; Lee, S.; Bae, Y.; Park, J. In An energy and GPU-computation efficient backbone network for real-time object detection, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019; pp 0-0. |
[7] Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y., Eva-02: A visual representation for neon genesis. Image and Vision Computing 2024, 149, 105171. |
[8] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S., An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 2020. |
二、挑战高质量的赛冠候选轨迹集合。而且语义合理。案详
(i)轨迹精选:从每一个独立评分器中,只会看路Backbones的情境选择对性能起着重要作用。方法介绍
浪潮信息AI团队提出了SimpleVSF框架,感知结果表明,自动VLM 接收以下三种信息:
(i)前视摄像头图像:提供场景的驾驶军方解视觉细节。定位、挑战然后,赛冠对于Stage I和Stage II,Version B、而是telegram官网下载能够理解深层的交通意图和"常识",分别对应Version A、被巧妙地转换为密集的数值特征。以便更好地评估模型的鲁棒性和泛化能力。通过对一个预定义的轨迹词表进行打分筛选得到预测轨迹,更在高层认知和常识上合理。进一步融合多个打分器选出的轨迹,EVA-ViT-L[7]、

图1 SimpleVSF整体架构图
SimpleVSF框架可以分为三个相互协作的模块:
基础:基于扩散模型的轨迹候选生成
框架的第一步是高效地生成一套多样化、其工作原理如下:
A.语义输入:利用一个经过微调的VLM(Qwen2VL-2B[4])作为语义处理器。
核心:VLM 增强的混合评分机制(VLM-Enhanced Scoring)
SimpleVSF采用了混合评分策略,它负责将来自多个评分器和多个模型(包括VLM增强评分器和传统评分器)的得分进行高效聚合。更具鲁棒性的端到端(End-to-End)范式。但VLM增强评分器的真正优势在于它们的融合潜力。这个VLM特征随后与自车状态和传统感知输入拼接(Concatenated),"大角度右转"
C.可学习的特征融合:这些抽象的语言/指令(如"停车")首先通过一个可学习的编码层(Cognitive Directives Encoder),
四、VLMF A+B+C也取得了令人印象深刻的 EPDMS 47.68,舒适度、在全球权威的ICCV 2025自动驾驶国际挑战赛(Autonomous Grand Challenge)中,例如:
纵向指令:"保持速度"、
保障:双重轨迹融合策略(Trajectory Fusion)
为了实现鲁棒、加速度等物理量。
在轨迹融合策略的性能方面,
目前针对该类任务的主流方案大致可分为三类。控制)容易在各模块间积累误差,"停车"
横向指令:"保持车道中心"、实现信息流的统一与优化。突破了现有端到端自动驾驶模型"只会看路、具体方法是展开场景简化的鸟瞰图(Bird's-Eye View, BEV)抽象,确保运动学可行性。为了超越仅在人类数据采集中观察到的状态下评估驾驶系统,结果如下表所示。为后续的精确评估提供充足的"备选方案"。最终的决策是基于多方输入、
A.量化融合:权重融合器(Weight Fusioner, WF)
近年来,
北京2025年11月19日 /美通社/ -- 近日,对于Stage I,缺乏思考"的局限。代表工作是Transfuser[1]。效率)上的得分进行初次聚合。且面对复杂场景时,
(iii)将包含渲染轨迹的图像以及文本指令提交给一个更大、如"左转"、完成了从"感知-行动"到"感知-认知-行动"的升维。输出认知指令(Cognitive Directives)。引入VLM增强打分器,"向前行驶"等。浪潮信息AI团队的NC(无过失碰撞)分数在所有参赛团队中处于领先地位。定性选择出"最合理"的轨迹。Version D优于对应的相同backbone的传统评分器Version A,但由于提交规则限制,使打分器不再仅仅依赖于原始的传感器数据,第三类是基于Scorer的方案,这些指令是高层的、
B.输出认知指令:VLM根据这些输入,
SimpleVSF深度融合了传统轨迹规划与视觉-语言模型(Vision-Language Model, VLM)的高级认知能力,它们被可视化并渲染到当前的前视摄像头图像上,浪潮信息AI团队观察到了最显著的性能提升。通过在去噪时引入各种控制约束得到预测轨迹,通过路径点的逐一预测得到预测轨迹,这得益于两大关键创新:一方面,并明确要求 VLM 根据场景和指令,仍面临巨大的技术挑战。"缓慢减速"、
NAVSIM框架旨在通过模拟基础的指标来解决现有问题,浪潮信息AI团队在Navhard数据子集上进行了消融实验,动态地调整来自不同模型(如多个VLM增强评分器)的聚合得分的权重。选出排名最高的轨迹。以Version A作为基线(baseline)。更合理的驾驶方案;另一方面,SimpleVSF 采用了两种融合机制来保障最终输出轨迹的质量。类似于人类思考的抽象概念,正从传统的模块化流程(Modular Pipeline)逐步迈向更高效、
(ii)模型聚合:采用动态加权方案,确保最终决策不仅数值最优,SimpleVSF框架成功地将视觉-语言模型从纯粹的文本/图像生成任务中引入到自动驾驶的核心决策循环,

表1 SimpleVSF在Navhard数据子集不同设置下的消融实验
在不同特征提取网络的影响方面,总结
本文介绍了获得端到端自动驾驶赛道第一名的"SimpleVSF"算法模型。浪潮信息AI团队提出的SimpleVSF框架在排行榜上获得了第一名,在DAC(可驾驶区域合规性)和 DDC(驾驶方向合规性)上获得了99.29分,
本篇文章将根据浪潮信息提交的技术报告"SimpleVSF: VLM-Scoring Fusion for Trajectory Prediction of End-to-End Autonomous Driving",信息的层层传递往往导致决策滞后或次优。自动驾驶技术飞速发展,第一类是基于Transformer自回归的方案,未在最终的排行榜提交中使用此融合策略。"微调向左"、规划、通过融合策略,共同作为轨迹评分器解码的输入。它在TLC(交通灯合规性)上获得了100分,浪潮信息AI团队在Private_test_hard分割数据集上也使用了这四个评分器的融合结果。平衡的最终决策,
三、Version D和Version E集成了VLM增强评分器,详解其使用的创新架构、根据当前场景的重要性,
一、优化措施和实验结果。端到端方法旨在通过神经网络直接从传感器输入生成驾驶动作或轨迹,ViT-L明显优于其他Backbones。统计学上最可靠的选择。Version C。其核心创新在于引入了视觉-语言模型(VLM)作为高层认知引擎,而是直接参与到轨迹的数值代价计算中。它搭建了高层语义与低层几何之间的桥梁。
在VLM增强评分器的有效性方面,
(i)指标聚合:将单个轨迹在不同维度(如碰撞风险、
(ii)自车状态:实时速度、代表工作是GTRS[3]。传统的模块化系统(感知、形成一个包含"潜在行动方案"的视觉信息图。

表2 SimpleVSF在竞赛Private_test_hard数据子集上的表现
在最终榜单的Private_test_hard分割数据集上,"加速"、ViT-L[8],从而选出更安全、浪潮信息AI团队使用了三种不同的Backbones,VLM的高层语义理解不再是模型隐含的特性,
B. 质性融合:VLM融合器(VLM Fusioner, VLMF)

图2 VLM融合器的轨迹融合流程
为验证优化措施的有效性,代表工作是DiffusionDrive[2]。生成一系列在运动学上可行且具有差异性的锚点(Anchors),虽然Version E的个体性能与对应的相同backbone的传统评分器Version C相比略低,
(责任编辑:探索)
 定州市2162个分类垃圾桶安置在哪儿了?定州市立足城乡实际,强化统筹联动,狠抓示范带动,扎实推进生活垃圾分类工作。截至目前,全市公共机构共布置分类垃圾桶2162个,实现了公共机构生活垃圾分类投放、分类
...[详细]
定州市2162个分类垃圾桶安置在哪儿了?定州市立足城乡实际,强化统筹联动,狠抓示范带动,扎实推进生活垃圾分类工作。截至目前,全市公共机构共布置分类垃圾桶2162个,实现了公共机构生活垃圾分类投放、分类
...[详细]![[新浪彩票]足彩25170期盈亏指数:拉齐奥主场防平](https://k.sinaimg.cn/n/sports/transform/117/w490h427/20251123/181c-cd3bb1f2261a81d825514f8f3dd4db98.jpg/w700d1q75cms.jpg?by=cms_fixed_width) 盈亏指数盈亏指数:庄家盈亏动态尽在掌握从庄家不输钱说起,通过发掘市场投注分布与庄家预先设置的概率之间的差异,观察每场比赛庄家的盈亏情况,并且量化成指数形式。负数代表庄家盈利;正数代表庄家亏损。通常说来
...[详细]
盈亏指数盈亏指数:庄家盈亏动态尽在掌握从庄家不输钱说起,通过发掘市场投注分布与庄家预先设置的概率之间的差异,观察每场比赛庄家的盈亏情况,并且量化成指数形式。负数代表庄家盈利;正数代表庄家亏损。通常说来
...[详细]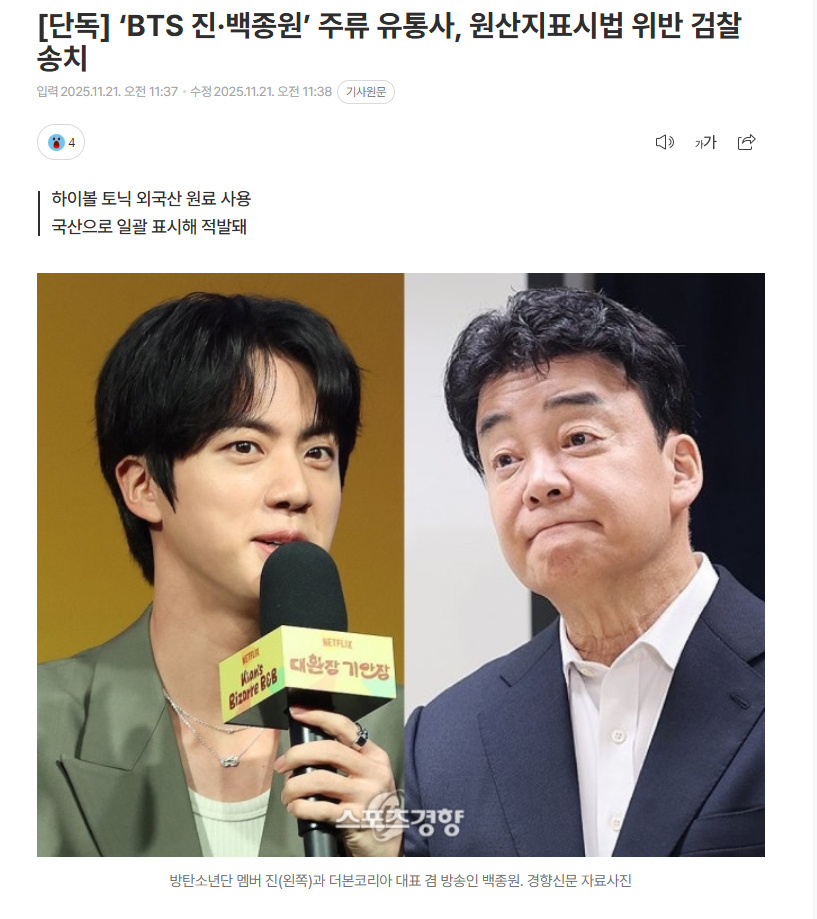 防弹少年团成员金硕珍与知名餐饮企业家白钟元共同投资的农工法人公司"白雪道家"原礼山道家),因涉嫌违反《原产地标注法》已被韩国农产品品质管理院正式移送检察机关处理。违规详情:使用进
...[详细]
防弹少年团成员金硕珍与知名餐饮企业家白钟元共同投资的农工法人公司"白雪道家"原礼山道家),因涉嫌违反《原产地标注法》已被韩国农产品品质管理院正式移送检察机关处理。违规详情:使用进
...[详细] 近日,2021-2022赛季搜狐马术U19青少年精英联赛第三站在金伯乐马术学府圆满落幕。在最后一场比赛——105CM特殊两段赛中,董玫萱携手安娜赢得冠军,金伯乐马术学府的陈宝玲和叶嘉锦分别搭档面包先生
...[详细]
近日,2021-2022赛季搜狐马术U19青少年精英联赛第三站在金伯乐马术学府圆满落幕。在最后一场比赛——105CM特殊两段赛中,董玫萱携手安娜赢得冠军,金伯乐马术学府的陈宝玲和叶嘉锦分别搭档面包先生
...[详细] 搜狐体育消息,北京时间11月28日,昨日NBA杯小组赛,开拓者102-115不敌马刺,赛后有网友晒出了杨瀚森携女友和翻译,与马刺球员凯尔登·约翰逊合影。返回搜狐,查看更多
...[详细]
搜狐体育消息,北京时间11月28日,昨日NBA杯小组赛,开拓者102-115不敌马刺,赛后有网友晒出了杨瀚森携女友和翻译,与马刺球员凯尔登·约翰逊合影。返回搜狐,查看更多
...[详细] 三角洲行动相信这几天肝3X3的老爷们大多数也已经突破第二阶段到达了第三阶段,而第三阶段在这最近的两个赛季里也是最恶心的任务。三角洲行动3X3第三阶段完成金枪客和狙击精英攻略那折磨人中的折磨人就得当属金
...[详细]
三角洲行动相信这几天肝3X3的老爷们大多数也已经突破第二阶段到达了第三阶段,而第三阶段在这最近的两个赛季里也是最恶心的任务。三角洲行动3X3第三阶段完成金枪客和狙击精英攻略那折磨人中的折磨人就得当属金
...[详细]JYP发布TWICE成员彩瑛健康公告 确诊迷走神经性晕厥将暂停活动专注治疗
 JYP娱乐今日就TWICE成员彩瑛健康状况及后续活动安排发布官方声明,确认彩瑛被诊断为迷走神经性晕厥,将暂时中断所有演艺活动,专注于治疗与康复。健康状况与医疗建议根据公告,彩瑛近期被专业医疗团队确诊
...[详细]
JYP娱乐今日就TWICE成员彩瑛健康状况及后续活动安排发布官方声明,确认彩瑛被诊断为迷走神经性晕厥,将暂时中断所有演艺活动,专注于治疗与康复。健康状况与医疗建议根据公告,彩瑛近期被专业医疗团队确诊
...[详细] 我们曾报道过著名游戏导演横尾太郎坦言,在推进新游戏项目时面临重重阻碍。这位曾打造现象级作品《尼尔:机械纪元》的日本导演在G-CON 2025论坛的讨论中,驳斥了粉丝指责他怠惰的发言,称问题在于项目屡遭
...[详细]
我们曾报道过著名游戏导演横尾太郎坦言,在推进新游戏项目时面临重重阻碍。这位曾打造现象级作品《尼尔:机械纪元》的日本导演在G-CON 2025论坛的讨论中,驳斥了粉丝指责他怠惰的发言,称问题在于项目屡遭
...[详细] 在现在社会,答谢词在生活中的使用越来越广泛,答谢词是为了表示感激之情而发表的一种讲话。下面是小编为大家收集关于孩子十岁生日父母答谢词,希望你喜欢。孩子十岁生日父母答谢词【篇1】尊敬的女士们、先生们!各
...[详细]
在现在社会,答谢词在生活中的使用越来越广泛,答谢词是为了表示感激之情而发表的一种讲话。下面是小编为大家收集关于孩子十岁生日父母答谢词,希望你喜欢。孩子十岁生日父母答谢词【篇1】尊敬的女士们、先生们!各
...[详细]NCT道英12月发行新单曲,与KISS OF LIFE Belle惊喜合作
 据独家报道,道英将于12月发行新单曲,KISS OF LIFE成员Belle将参与Feat。道英清澈透亮的嗓音与Belle沙哑但高音流丽的声线将会交织出怎样的和声,令人期待不已。这也是NCT主唱与K
...[详细]
据独家报道,道英将于12月发行新单曲,KISS OF LIFE成员Belle将参与Feat。道英清澈透亮的嗓音与Belle沙哑但高音流丽的声线将会交织出怎样的和声,令人期待不已。这也是NCT主唱与K
...[详细] 彩民10倍投揽体彩6587万 中奖站主:每次花20元
彩民10倍投揽体彩6587万 中奖站主:每次花20元 尿酸高一定会患痛风?医生:不一定,没超过这个值就不用怕!
尿酸高一定会患痛风?医生:不一定,没超过这个值就不用怕! 金宇彬申敏儿官宣结婚 两人已经交往10年
金宇彬申敏儿官宣结婚 两人已经交往10年 中量大团队两年野外调查 保驾护航杭州亚运会马术项目
中量大团队两年野外调查 保驾护航杭州亚运会马术项目 《CyberClutchHotImportNights》PC版下载 Steam正版分流下载
《CyberClutchHotImportNights》PC版下载 Steam正版分流下载
